Neste post vamos comentar brevemente sobre relaxações de formulações lineares inteiras e focar especialmente em relaxações lagrangeanas. Depois, vamos demonstrar a aplicação dessa técnica no problema da localização de instalações (facility location). A menos que dito o contrário, estamos falando de problemas de minimização.
Relaxações
Em programação linear inteira, usamos o termo relaxação para indicar que algumas das restrições do problema original foram relaxadas. Provavelmente o exemplo mais conhecido de relaxação é o da relaxação linear. Nesse caso em particular, removemos as restrições de integralidade do modelo.
Mais formalmente, se tivermos uma formulação 

sendo 
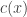

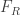

é uma relaxação se todo ponto de 
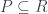

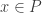
Note que devido a essas propriedades, a solução ótima da relaxação é um limitante dual (ou seja, no nosso caso é um limite inferior e superior no de maximização) para a formulação original ou seja, 
A vantagem de se usar relaxações é que em certos casos elas são mais fáceis de serem resolvidas. Por exemplo, as relaxações lineares podem ser resolvidas em tempo polinomial, enquanto a versão restrita a inteiros, em geral, é NP-difícil.
Podemos também relaxar uma formulação removendo algumas de suas restrições. Note, entretanto, que quanto mais relaxamos a formulação pior tende a ser a qualidade do limitante dual (considere o caso extremo onde removemos todas as desigualdades do modelo: não deixa de ser uma relaxação, mas o limitante dual obtido não serve para nada).
O ideal é que encontremos uma relaxação fácil de resolver e que dê limitantes duais de qualidade, ou seja, bem próximos do valor ótimo da formulação original.
Relaxação Lagrangeana
Existe uma técnica denominada relaxação lagrangeana [1], que consiste em remover algumas das restrições da formulação original, mas tenta embutir essas desigualdades na função objetivo. A ideia é penalizar a função objetivo quando as restrições removidas forem violadas. O “peso” dessas penalidades é controlado por coeficientes chamados multiplicadores lagrangeanos.
Em termos de matemáticos, suponha que tenhamos uma formulação com 

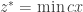
Sujeito a
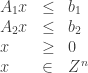
Onde 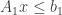

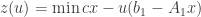
Sujeito a
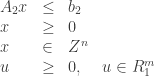
Onde 


Ao remover (11), o seguinte fator é subtraído da função objetivo
(1)

Note que quanto mais “violada” a desigualdade estiver, mais negativo o termo (1) vai ficar. Como a função é de minimização e estamos subtraindo, intuitivamente a solução ótima para o problema tenderá a não violar as desigualdades, melhorando o resultado do limitante dual.
Escolhe-se remover as desigualdades de forma que o problema resultante seja mais fácil resolver para um valor fixo de multiplicadores lagrangeanos. Porém, agora temos que resolver um outro problema: encontrar um conjunto de multiplicadores lagrangeanos 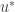

Aplicação ao problema da localização de instalações
O problema da localização de instalações é bastante estudado na literatura. Uma de minhas iniciações científicas consistia em estudar algoritmos aproximados para esse problema.
Basicamente temos um grafo bipartido onde uma partição corresponde ao conjunto de clientes 

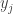
Vamos apresentar uma formulação linear inteira para esse problema. Seja 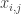
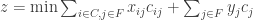
Sujeito a
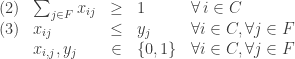
A desigualdade (2) diz que cada cliente deve ser atendido por pelo menos uma fábrica e a desigualdade (3), que uma fábrica deve estar aberta para que possa atender a algum cliente.
Essa é uma formulação bem simples e temos basicamente dois grupos de desigualdades. Vamos tentar relaxar o grupo de desigualdades indicado por (2). Teremos:
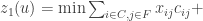

Sujeito a
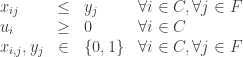
Com um pouco de álgebra, é possível “fatorar” o somatório da função objetivo:

Como o termo 
Desta forma, podemos decompor essa formulação por cada fábrica
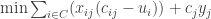
Sujeito a:

Cada um desses problemas pode ser resolvido por inspeção. Seja 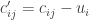


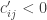
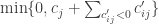
A outra alternativa consiste em relaxar a desigualdade (3). Nesse caso, depois de alguma álgebra, teremos:

Sujeito a:

Note que como não há restrições misturando 

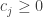
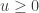


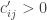
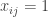
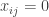
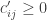

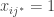
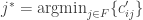
Temos duas formulações que podem ser facilmente resolvidas. Entretanto, devemos levar em conta qual possui a formulação mais forte. Em outras palavras, dado 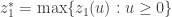

Conclusão
A relaxação Lagrangeana é uma técnica poderosa para se obter limitantes duais de problemas combinatórios que podem ser modelados como programas lineares inteiros. Esses limitantes podem ser usados na tentativa de melhorar o desempenho de algoritmos branch-and-bound.
Além do mais, para certos problemas, existe a possibilidade de ajustar a solução obtida via relaxação de modo a obter uma solução viável para o problema original, esperando que a qualidade da solução não seja muito pior.
Esse post apresentou a teoria por trás da relaxação lagrangeana. Num próximo post vou apresentar uma heurística que visa encontrar bons multiplicadores lagrangeanos.
Referências
[1] The Lagrangian relaxation method for solving integer programming problems – M.L. Fisher Management Science, 1981.



 Publicado por kunigami
Publicado por kunigami 
 o número total de pontos que nosso time tem após todas essas considerações. Observe que
o número total de pontos que nosso time tem após todas essas considerações. Observe que 










 Feed dos posts
Feed dos posts
Deverá estar ligado para publicar um comentário.