Já faz um tempo que ocorreu o SRM 517, mas só agora resolvi estudar a solução. No dia resolvi só problema mais fácil (250) e ainda errei um challenge :(
Neste post vou apresentar apenas a solução do problema médio, que estava mais difícil do que o normal, o que estava sugerido por sua pontuação (600 ao invés de 500).
Adjacent swaps
Descrição
Seja um vetor de N elementos v = {0, 1, 2, …, N-1} e uma permutação de p = {p[0], p[1], …, p[N-1]} de v. Definimos como troca-completa o conjunto das N-1 possíveis trocas entre elementos nas posições i e e i+1 (i variando de 0 a N-2) executadas exatamente uma vez, em uma ordem arbitrária.
O problema pede para encontrar quantas trocas-completas levam a v a p.
Solução
A primeira observação é que ao invés de considerar trocas-completas que levem v a p, consideramos aquelas que levam p a v. Existe uma bijeção entre uma troca-completa do problema original e do novo problema, que é simplesmente inverter a ordem das trocas e portanto a resposta é a mesma para os dois problemas.
A solução proposta no editorial é resolver esse problema através de programação dinâmica. Para tanto, definimos
u(i,j, k) — como o número de trocas-completas que ordenam o subvetor p[i…j] = {p[i], p[i+1] …, p[j]}, usando apenas as trocas entre elementos consecutivos entre i e j-1, com a restrição adicional de que a última troca efetuada seja entre k e k+1. (0 <= i <= k < j <= N-1).
Seja 
Vamos ver como podemos calcular u(i,j,k).
Seja q[i…j] o subvetor p[i…j] ordenado e q'[i..j] o subvetor q[i..j] antes de fazer a troca entre k e k+1. Assim, q'[k] = q[k+1] e q'[k+1] = q[k], ou seja q'[i…j] = {q[i], q[i+1], …, q[k-1], q[k+1], q[k], q[k+2], …, q[j]}.
Observação 1: (q[i] < q[i+1] < … q[k-1] < q[k+1]) e (q[k] < q[k+2] < … < q[j]).
Por definição, q[i…j] e q'[i…j] são permutações de p[i..j]. Isso implica que todo elemento de q'[i…k] pertence a p[i…k] ou p[k+1…j]. Porém, como por hipótese a troca k,k+1 não foi feita ainda, um elemento de q'[i…k] não pode ter vindo de p[k+1…j]. Logo, concluímos que q'[i…k] deve ser uma permutação de p[i…k]. Temos assim duas condições a serem satisfeitas:
Condição 1: O subvetor p[i…k] deve ser uma permutação de q'[i…k].
Condição 2: O subvetor p[k+1…j] deve ser uma permutação de q'[k+1…j].
Na verdade podemos mostrar que as condições 1 e 2 são equivalentes. Supondo que as condições são satisfeitas, pela Observação 1, temos que q'[i…k] está ordenado, logo q'[i…k] = q[i…k], que é uma ordenação de p[i…k]. É possível argumentar o mesmo para q'[k+1…j] e p[k+1…j].
Por definição, t(i,k) conta o número de trocas-completas que leva p[i…k] em q[i…k] (o mesmo para t(k+1,j)). Assim, a princípio poderíamos combinar cada troca-completa em t(i,k) com cada troca-completa em t(k+1,j), levando à recorrência u(i, j, k) = t(i, k)*t(k+1, j).
Entretanto, há um número bem maior de combinações. Considere uma dada troca-completa A de t(i,k) e outra B de t(k+1, j). Embora a ordem das trocas em A e em B sejam fixas, não há restrição de ordem entre uma troca feita em A e outra feita em B. Por exemplo, poderíamos fazer todas as trocas de A primeiro e depois todas as de B ou qualquer combinação de intercalação entre os elementos de A e B.
Podemos mostrar que o número total de intercalações possíveis é dada por um coeficiente binomial C(n,r). No nosso caso em particular, n é o número total de trocas disponíveis, ou seja, j-i-1 (k-i de A e j-(k+1) de B) e r é o número de trocas em A (ou em B), ou seja, C(j-i-1, k-i). Para ver o porquê, considere que temos posições de 1 a j-i-1. Queremos escolher k-i dessas posições para atribuir a elementos de A e o restante das posições fica para B. Agora basta pensarmos nessas posições como a ordem em que as trocas são efetuadas.
Isso dá a recorrência
u(i, j, k) = t(i, k)*t(k+1, j)*C(j-i-1, k-i)
No caso de as condições 1 e 2 não serem satisfeitas, u(i, j, k) = 0.
Podemos usar a recorrência C(n,r) = C(n-1, r-1) + C(n-1, r) para pré-computar os valores dos coeficiente binomiais em 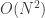

Dado isso, podemos computar cada u(i, j, k) em 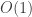

Decidi colocar minhas implementações de SRM’s também no github.
Conclusão
Achei a solução desse problema bastante complicada e como de costume fiquei surpreso de tanta gente ter conseguido resolvê-lo durante os 75 minutos de competição.
Programação dinâmica é uma técnica que eu acho difícil aprender, porque em geral não consigo encontrar uma estrutura no problema que me indique a forma de atacá-lo. Minha esperança é continuar estudando suas aplicações e quem sabe aprender por “osmose” :P
O uso do coeficiente binomial para contar intercalações é bem engenhoso! Lembro que alguma outra vez estudei um problema em que a contagem por coeficiente binomial também não era trivial de ver.



 Publicado por kunigami
Publicado por kunigami 





 Feed dos posts
Feed dos posts
Deverá estar ligado para publicar um comentário.