Agora que estamos no final do ano, vou fazer uma retrospectiva dos principais acontecimentos de 2011.
Primeiro Semestre
O primeiro semestre foi bastante cansativo, mas também produtivo.
Artigos. Escrever artigos é uma das coisas que mais me motivam do meio acadêmico. Desde o final de 2010 estávamos escrevendo um artigo que acabou sendo aceito em uma conferência chamada CGA (Computational Geometry Applications). Logo no começo do ano, um resumo estendido nosso foi aceito no CTW (Cologne-Twente Workshop). Quando comecei a escrever minha dissertação, enxergamos a possibilidade de escrever ainda outro artigo, que foi aceito no Sibigrapi. Mais detalhes aqui.
Google Summer of Code. Durante o primeiro semestre, fui aceito no Google Summer of Code, para trabalhar com um projeto de computação gráfica. Tive que conciliar esse projeto com a escrita da minha dissertação e a escrita para o Sibgrapi! Felizmente, no final deu tudo certo. Escrevi vários posts sobre esse projeto.
Google Code Jam. Não consegui me classificar para a penúltima fase, mas acabei ficando entre os 1000 classificados e ganhando uma camiseta :)
Sibgrapi. Fui apresentar nosso artigo aceito para o Sibgrapi em Maceió. Foi meu primeiro congresso e a primeira vez que apresentei em inglês e para um público grande. Escrevi um post contando mais sobre o evento.
Defesa do mestrado. Depois de aproximadamente 2 anos de trabalho árduo conclui meu projeto de mestrado com a defesa da minha tese.
Emprego em otimização. Graças à indicação do Carlos, estou trabalhando em uma empresa de otimização. Até o momento estou aprendendo bastante sobre desenvolvimento de software em Java, além de ler artigos e implementar soluções para problemas de escalonamento.
Segundo Semestre
No restante do segundo semestre as coisas foram bem mais calmas.
Codefest. Participamos de uma competição onde deveríamos atacar um problema de otimização, tendo duas semanas para implementar uma solução. No final deixamos de levar o prêmio devido a uma bobeira, conforme descrevi aqui.
Haskell. Decidi começar a aprender Haskell com o objetivo de melhorar minhas habilidades de programação. Tenho me surpreendido com a elegância de alguns trechos de código que tenho visto e com a própria sintaxe da linguagem.
Blog
O blog está prestes a completar 3 anos e contando com esse post, são 97 no total. Tenho conseguido manter minha resolução de postar uma vez por semana.
Os posts mais acessados este ano foram: Algoritmo de Branch and Cut, Ponto dentro de polígono e Dijkstra e o caminho máximo.
Os termos mais utilizados em engines de busca foram: “soccer“, “aisec” e “ray tracing“. Um termo de busca curioso é “obter o poligono simetrico cgal“, que apareceu 89 vezes e eu nem faço ideia do que seja isso!
O blog teve, em média, 42 visitas por dia, com um total de 16k desde o seu início. O dia com mais visitas foi 30 de Novembro com 104 visitantes.
Resoluções para 2012
Para 2012, já me matriculei em dois cursos online de Stanford: Probabilist Graphical Models e Natural Language Processing.
Eu gostaria de aprender mais sobre mineração de dados (data mining) voltado ao suporte de tomada de decisões e também sobre otimização/programação estocástica, que considera fatores de incerteza, muito presentes nos problemas que atacamos na indústria. Dado isso, acho que o curso de modelos gráficos probabilísticos ajudará a reforçar minha base de probabilidade (que é bem fraca).
O curso de processamento de linguagem natural eu peguei mais por curiosidade e ainda não decidi se vou realmente fazer.



 Publicado por kunigami
Publicado por kunigami  , criar um subgrafo
, criar um subgrafo 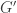 contendo apenas as arestas de custo menores ou iguais a
contendo apenas as arestas de custo menores ou iguais a  onde
onde  é o número de vértices e
é o número de vértices e  é o número de arestas.
é o número de arestas. ) e nesse caso o grafo bipartido teria
) e nesse caso o grafo bipartido teria 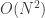 arestas, levando a uma complexidade total
arestas, levando a uma complexidade total  . No problema o valor de
. No problema o valor de  , é possível construir uma árvore de N vértices, de forma que exista uma correspondência entre os graus dos vértices e os elementos desse vetor.
, é possível construir uma árvore de N vértices, de forma que exista uma correspondência entre os graus dos vértices e os elementos desse vetor. , temos os vetores [3, 1, 1, 1] e [2, 2, 1, 1] e suas permutações. Dado um vetor, seu custo é dado pela soma dos pesos de seus elementos. O problema original então se reduz a encontrar o maior custo de um vetor satisfazendo as restrições da proposição.
, temos os vetores [3, 1, 1, 1] e [2, 2, 1, 1] e suas permutações. Dado um vetor, seu custo é dado pela soma dos pesos de seus elementos. O problema original então se reduz a encontrar o maior custo de um vetor satisfazendo as restrições da proposição. como a melhor solução de um vetor de
como a melhor solução de um vetor de  elementos e somando exatamente
elementos e somando exatamente  . A recorrência fica:
. A recorrência fica: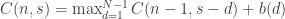
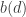 é o valor do elemento
é o valor do elemento  (dado pelo vetor
(dado pelo vetor 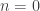 . Nesse caso, se
. Nesse caso, se 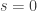 , temos 0, caso contrário não existe solução e retornamos
, temos 0, caso contrário não existe solução e retornamos  .
.  , seja
, seja  o número de elementos com valor maior ou igual a 2. Crie um nó raíz com
o número de elementos com valor maior ou igual a 2. Crie um nó raíz com 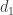 filhos. Faça um desses filhos ter
filhos. Faça um desses filhos ter  filhos, um dos “netos” ter
filhos, um dos “netos” ter 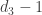 filhos e assim sucessivamente, até um nó ter
filhos e assim sucessivamente, até um nó ter  filhos.
filhos.
 e o resto dos nós têm grau 1. Resta provar que o número desses nós de grau 1 é exatamente
e o resto dos nós têm grau 1. Resta provar que o número desses nós de grau 1 é exatamente  , ou equivalentemente, que essa árvore tem
, ou equivalentemente, que essa árvore tem 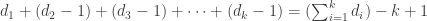 .
. é o número de nós da árvore gerada, temos
é o número de nós da árvore gerada, temos 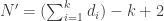 .
.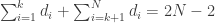

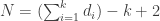 e que
e que 

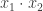 , em uma equação linear. Há três casos que devemos considerar: quando ambas variáveis são binárias; quando uma das variáveis é binária e a outra é contínua; e quando as duas variáveis são contínuas.
, em uma equação linear. Há três casos que devemos considerar: quando ambas variáveis são binárias; quando uma das variáveis é binária e a outra é contínua; e quando as duas variáveis são contínuas. e
e  são binárias, a modelagem é fácil:
são binárias, a modelagem é fácil:

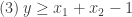

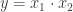 .
. . Temos:
. Temos:
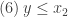
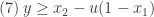
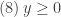
 , temos que
, temos que  . Se
. Se  , então (7) vira
, então (7) vira  , que combinado com (6), implica
, que combinado com (6), implica 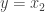 .
.
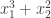 é separável, mas
é separável, mas  não é.
não é. do somatório. Suponha que aproximamos
do somatório. Suponha que aproximamos  , com intervalos definidos pelos pontos
, com intervalos definidos pelos pontos  , sendo que a função
, sendo que a função  e
e 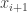 é linear.
é linear. através de programação linear. Para isso, considere as variáveis contínuas
através de programação linear. Para isso, considere as variáveis contínuas  , tal que
, tal que  . Temos então
. Temos então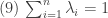

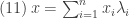
 ‘s sejam não nulos e no caso de serem dois, esses
‘s sejam não nulos e no caso de serem dois, esses 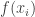 . No caso de
. No caso de  serem não nulos, eles representam
serem não nulos, eles representam  e
e  .
. ,
, ![[x', f(x')]](https://s0.wp.com/latex.php?latex=%5Bx%27%2C+f%28x%27%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) é uma combinação convexa de
é uma combinação convexa de ![[x_i, f(x_i)]](https://s0.wp.com/latex.php?latex=%5Bx_i%2C+f%28x_i%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) e
e ![[x_{i+1}, f(x_{i+1})]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bi%2B1%7D%2C+f%28x_%7Bi%2B1%7D%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) e portanto pertence à reta que une esses dois pontos.
e portanto pertence à reta que une esses dois pontos.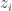 para
para  . Temos que
. Temos que 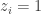 se e somente se, o valor de
se e somente se, o valor de  está entre
está entre 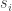 para
para  . Nesse caso
. Nesse caso 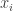 e
e  para
para  e
e 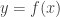 , temos o seguinte conjunto de restrições:
, temos o seguinte conjunto de restrições:



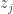 será igual a 1 (e o resto zero). Nesse caso, (14) reduzirá para:
será igual a 1 (e o resto zero). Nesse caso, (14) reduzirá para: ,
, 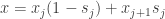

![[x, y]](https://s0.wp.com/latex.php?latex=%5Bx%2C+y%5D&bg=ffffff&fg=333333&s=0&c=20201002) é combinação convexa de
é combinação convexa de ![[x_j, y_j]](https://s0.wp.com/latex.php?latex=%5Bx_j%2C+y_j%5D&bg=ffffff&fg=333333&s=0&c=20201002) e
e ![[x_{j+1}, y_{j+1}]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bj%2B1%7D%2C+y_%7Bj%2B1%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
. e
e  . Agora é fácil ver que
. Agora é fácil ver que  , e é uma função separável.
, e é uma função separável. 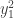 usando
usando ![[{y_1}_i, {y_1}_i^2]](https://s0.wp.com/latex.php?latex=%5B%7By_1%7D_i%2C+%7By_1%7D_i%5E2%5D&bg=ffffff&fg=333333&s=0&c=20201002) para
para  . Agora basta substituir ocorrência de
. Agora basta substituir ocorrência de 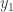 pelo ‘x’ de (14) e
pelo ‘x’ de (14) e  .
. Feed dos posts
Feed dos posts
Deverá estar ligado para publicar um comentário.